
Intro:
Another great exercise assignment #3[1] presented by Berkeley’s DRL course, where the assignment pushes students to implement(kind of) and train the DQN algorithm presented in 2013, by Mnih et al, in the paper “Playing Atari with Deep Reinforcement Learning”. [2] The implementation uses off-policy training, with experience replay, epsilon greedy exploration, and the use of an additional target network for stabilization (introduced in later papers). The relevant lectures by John Schulman can be found at CS294-112 2/15/2017 and CS294 2/22/2017
source: DQN
Review:
A considerable amount of the code was provided(kudos to Szymon Sidor from OpenAI), and the student is left to implement a few key portions in tensorflow. Specifically, the student is left to implement the update of the replay buffer, sampling of the replay buffer, definition of the error value used for optimization, target network updates, and set up of the training step to train the deep convolutional neural network used to approximate the Q-function that generates an estimate of the state-value function for a given state and action.
The implementation was more of an exercise in getting a handle on the starter code, and understanding the API of the relevant objects found in the system. As a result, one should derive in an increased understanding of tensorflow, (numpy + python to say the least), in addition to a greater appreciation for the abstraction that Keras + other frameworks provides.
Further, knowing that training the model would require 1 million + steps, GPU acceleration is pretty much a must for fast experimentation. This GPU access was not provided, and is left to the student to source. (May be different for enrolled Berkeley students.) I decided on using the AMI provided by bitfusion.io, “Bitfusion Ubuntu 14 Tensorflow” where a g2.2xlarge costs $0.715/hr (includes software costs of $0.065). Wanting to initially avoid paying up for the $0.065 cost of software, I attempted a supposed cheaper route by starting with a bare bones Ubuntu 14.04 AMI, and building necessary software myself. I failed miserably and crawled back to bitfusion.io. (Lesson here is dont be a “@#@$ for a tick”)
Thank you bitfusion.io! as the AMI is decked…
Ubuntu 14 AMI pre-installed with Nvidia Drivers, Cuda 7.5 Toolkit, cuDNN 5.1, TensorFlow 1.0.0, TFLearn, TensorFlow Serving, TensorFlow TensorBoard, Keras, Magenta, scikit-learn, Python 2 & 3 support, Hyperas, PyCuda, Pandas, NumPy, SciPy, Matplotlib, h5py, Enum34, SymPy, OpenCV and Jupyter to leverage Nvidia GPU as well as CPU instances.
After gaining access to the instance through an ssh via my command-line, all
that was left was a sudo -H pip install gym[atari] and copying the relevant
files over. I really wish I would have started with this in hindsight. (I am in
no way associated with bitfusion.io fwiw, nor Berkeley for that matter.)
Once the required code was implemented and the GPU access set up appropriately, the rest was just about hitting the start button to initiate training.
DQN algorithm:

CNN model:
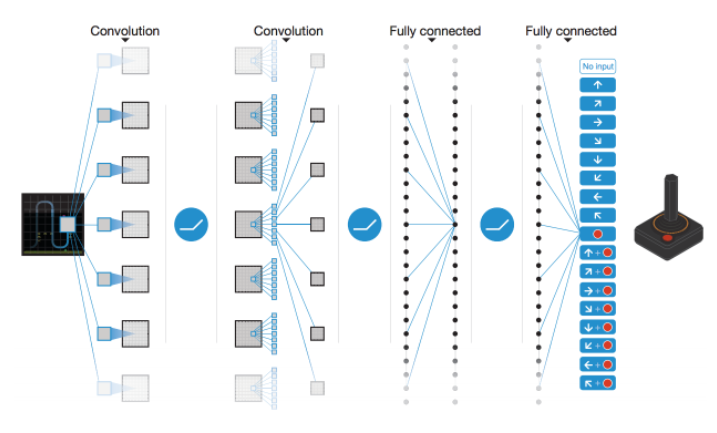
Key Points/Concepts:
- Algorithm is hybrid of online and batch Q-value iteration, interleaves optimization with data collection.
- Replay memory for increased data efficiency, increased stability, reward propagation beyond 1-step, and addresses the concerns around i.i.d breakdown associated with purely online updates.
- Target network fixed over timesteps (~10k steps) to approximate \(Q(s_{t+1},a_{t+1})\). John comments that this allows \(Q\) to chase a relatively non-moving target (\(Q\) chases \(TQ\)). Another way to think about this in my own words is that: \(r + \gamma * max Q(s_{t+1},a_{t+1})\) has 1 time step of real world data derived from \(r\), when compared to \(Q(s,a)\), and is a better estimate of the expected return under a given policy at time step \(t\) from a particular state,\(s\) after taking action \(a\). We want \(Q(s_t,a_t)\) to better approximate the expected return, or said differently catch up to \(r+ \gamma * max Q(s_{t+1},a_{t+1})\), thus as in any situation, a slow moving target is easier to catch than a fast moving target.
Results:
Ideally testing different parameter settings is recommended, but considering personal time constraints, I left the parameters at default values.
- Replay buffer size: 1m
- Exploration: epsilon linear decay, floor at 0.1
- Target network: 10k step updates
- Gamma: 0.99
- Batch size: 32
- Frame history length: 4
- Gradient norm clipping: 10
The default settings were sufficient to produce acceptable results, as we see
the AI agent is able to start scoring against the opponent.
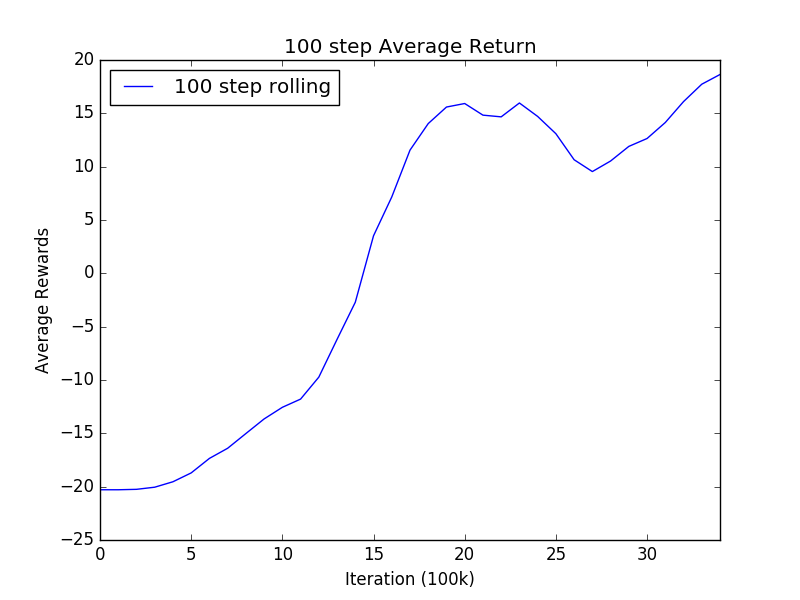
The following video is after the agent had consistently starting scoring on average.
Modifications:
A few suggestions were made based off subsequent published papers that have shown to speed up training times and general performance. (Note: not implemented.)
- Double DQN:[3] use \(r + \gamma * Q^{target}(s’,Q(s’,a’))\) for the target Q-value.
- Dueling nets:[4] parameterize \(Q\) as \(Q_\theta(s,a) = V_{\theta}(s) + F_{\theta}(s,a) - mean_{a’}F_{\theta}(s,a’)\)
- Prioritized Experience:[5] Use last bellman error to estimate gradient step, and use update value for either proportional, \(p_i =|\delta_i| + \epsilon\) or rank, \(p_i = \frac{1}{rank_i}\) weighting.
Final Thoughts:
With relatively cheap access to GPU acceleration, very accessible starter code, and great insight from publicly available lectures, any one can implement a history making algorithm, given the time and patience. This is great, and I hope that more first class institutions continue to share such high quality material to the general public.
References
- Deep RL Assignment 3: Q-Learning on Atari. http://rll.berkeley.edu/deeprlcourse/docs/hw3.pdf
- Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Graves, Alex, Antonoglou, Ioannis, Wierstra, Daan, and Riedmiller, Martin. Playing atari with deep reinforcement learning. arXiv:1312.5602, 2013.
- Van Hasselt, H., Guez, A., and Silver, D. Deep reinforcement learning with double Q-learning, 2015
- Wang, Z., de Freitas, N., Lanctot, M. Dueling network architectures for deep reinforcement learning arXiv preprint arXiv: 1511.06581
- Schaul, T., Quan, J., Antonoglou, I., and Silver, D., Prioritized experience replay. arXiv preprint arXiv:1511.05952(2015)